
Redis缓存雪崩,缓存穿透,缓存击穿
编辑缓存穿透的解决方案
什么是缓存穿透?
缓存穿透就是客户端请求没有经过缓存服务直接访问数据库了,通常
就是查询的时候key在Redis中不存在,对应的ID在数据库也不存在,此时被非法用户进行攻击,大量的请求会直接打在db上,造成宕机从而影响整个系统,这种现象称之为缓存穿透,
常用解决方案:
- 接口层增加校验,如用户鉴权校验,id做基础校验,例如id<=0的直接拦截或者id位数不够的直接拦截;
- 客户端首次访问数据库,当数据不存在的时候也存入空数据(空字符串,空对象或者空集合)到缓存,设置过期时间,这样在频繁请求的时候会访问到缓存;后续如果数据存在了则会覆盖当前的空数据,所以就可以访问到新数据了
//首先引入guava工具类
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.1-jre</version>
</dependency>
List<CategoryVO> categories = null;
String catsStr = redisOperator.get("subCat:"+rootCatId);
if (StringUtils.isBlank(catsStr)){
categories = categoryService.getSubCatList(rootCatId);
if (categories != null && categories.size() > 0){
redisOperator.set("subCat:"+rootCatId,JsonUtils.objectToJson(categories));
} else {
redisOperator.set("subCat:"+rootCatId,JsonUtils.objectToJson(categories),5*60);
}
}else {
categories = JsonUtils.jsonToList(catsStr,CategoryVO.class);
}
缓存穿透之布隆过滤器
什么是布隆过滤器? 迅速判断某一个元素是否在集合里面,布隆过滤器本质是很小的二进制数组,是以二进制的形式做的存储(0代表不存在,1代表存在),所占的内存很小,添加和查询是极快的,常用于邮件短信的拦截和缓存穿透;
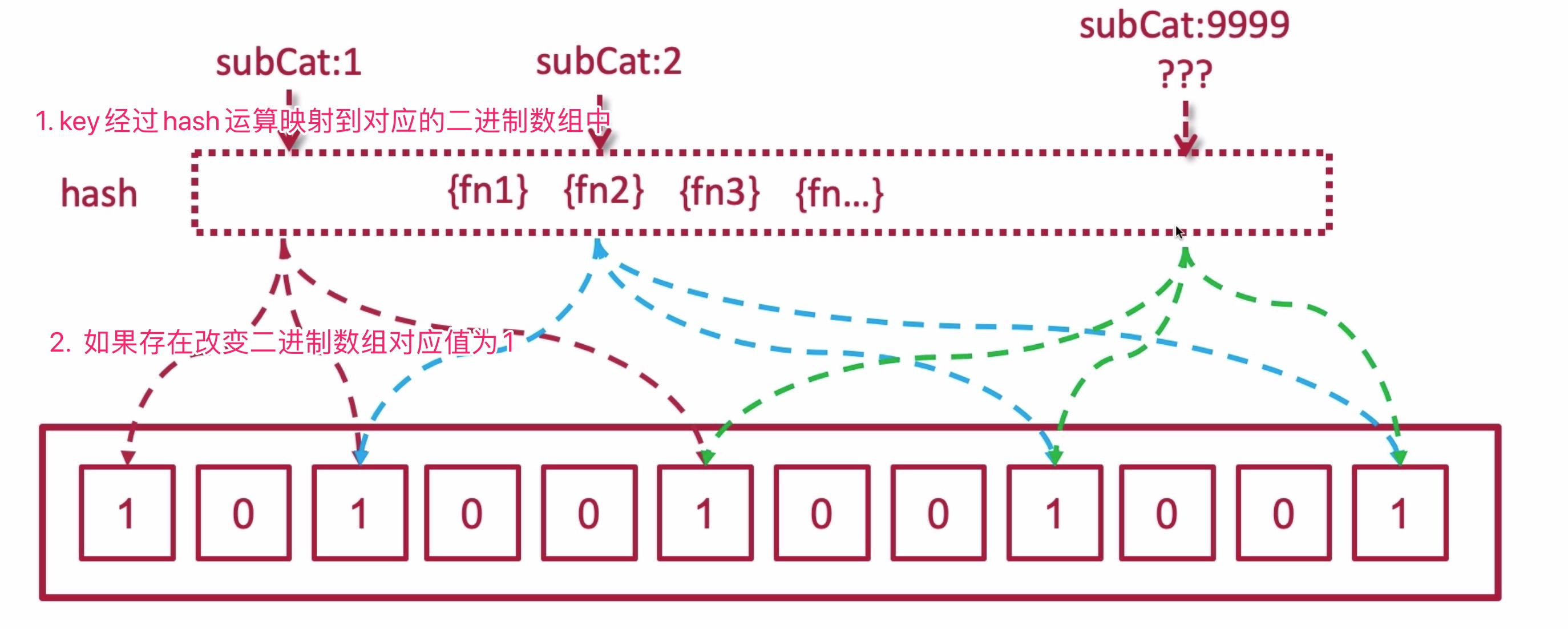
布隆过滤器的基本思想
- 当布隆过滤器说某个值存在时,这个值可能不存在,有一定的几率会出现误判;当它说不存在时,那就肯定不存在。
- 布隆过滤器不能删除的,因为不同的key经过不同hash运算之后(随机运行函数)的值可能映射相同的地址,如果删除,会影响其他的key的判断准确性;
使用布隆过滤器
@Test
public void test(){
//创建一个布隆过滤器,第一个参数字符集;
// 第二个参数期待是插入的长度,长度越长误判率越低,但是占用的内存越高
// 第三个参数 ,误判率,会根据设置做出相应的调整
BloomFilter bf = BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")),
100000,0.0001);
for (int i = 0; i <100000 ; i++) {
bf.put(String.valueOf(i));
}
int count = 0;
for (int i = 0; i < 1000; i++) {
boolean isExist = bf.mightContain("misty"+i);
if (isExist){
count ++;
}
}
System.out.println("误判率:"+count);
}
缓存雪崩与预防
什么是缓存雪崩?
缓存中大量的key失效,大量的流量直接访问数据库的情况,容易导致数据库宕机;
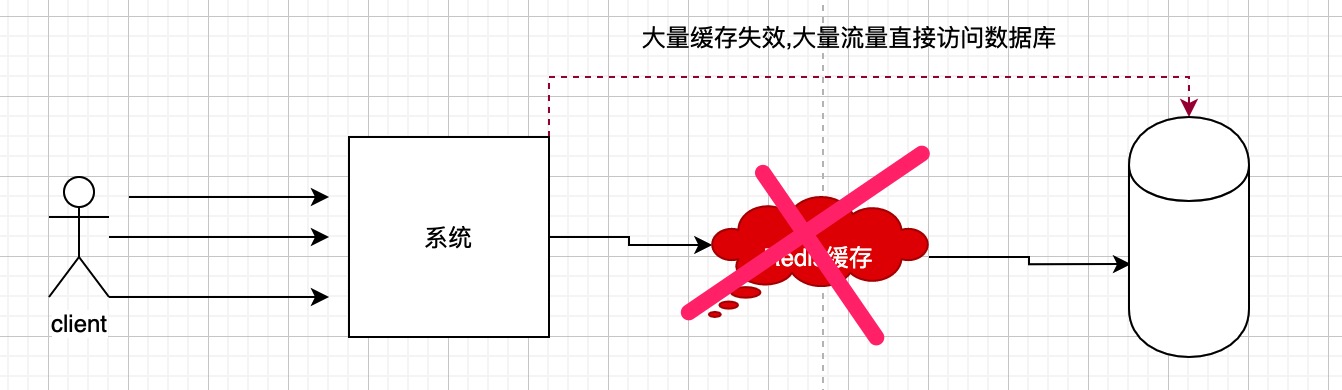
雪崩预防
缓存雪崩不能完全解决,只能预防缓解提前防护;
- 缓存永不过期:除了验证码这种临时的不会入库的数据设置过期时间,其他可以设置永不过期,或者手动过期,这样不会出现缓存大面积失效的情况;
- 过期时间错开:过期时间错开达到时间错峰的效果;
- 多缓存结合:
redis ->memcache->db先访问Redis,有数据直接返回,没有再访问其他缓存,所有的缓存都没有再访问数据库; - 采购第三方redis
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机; 缓存击穿指并发查同一条数据
缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多(热点数据),同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力;
解决方案:
**1.**设置热点数据永远不过期。
2. 加互斥锁:缓存中有数据,直接返回结果,缓存中没有数据,第1个进入的线程,获取锁并从数据库去取数据,没释放锁之前,其他并行进入的线程会等待,再重新去缓存取数据。这样就防止都去数据库重复取数据,重复往缓存中更新数据情况出现。
static Lock reenLock = new ReentrantLock();
public List<String> getData04() throws InterruptedException {
List<String> result = new ArrayList<String>();
// 从缓存读取数据
result = getDataFromCache();
if (result.isEmpty()) {
if (reenLock.tryLock()) {
try {
System.out.println("我拿到锁了,从DB获取数据库后写入缓存");
// 从数据库查询数据
result = getDataFromDB();
// 将查询到的数据写入缓存
setDataToCache(result);
} finally {
reenLock.unlock();// 释放锁
}
} else {
result = getDataFromCache();// 先查一下缓存
if (result.isEmpty()) {
System.out.println("我没拿到锁,缓存也没数据,先小憩一下");
Thread.sleep(100);// 小憩一会儿
return getData04();// 重试
}
}
}
return result;
}
3. 后台定义一个job(定时任务)专门主动更新缓存数据.比如,一个缓存中的数据过期时间是30分钟,那么job每隔29分钟定时刷新数据(将从数据库中查到的数据更新到缓存中).注:这种方案比较容易理解,但会增加系统复杂度。比较适合那些 key 相对固定,cache 粒度较大的业务,key 比较分散的则不太适合,实现起来也比较复杂;
4. 在实际分布式场景中,我们还可以使用 redis、tair、zookeeper 等提供的分布式锁来实现.但是,如果我们的并发量如果只有几千的话,何必杀鸡焉用牛刀呢?
multiGet 批量查询优化
/**
* 批量查询,对应mget
* @param keys
* @return
*/
public List<String> mget(List<String> keys) {
return redisTemplate.opsForValue().multiGet(keys);
}
@GetMapping("/mget")
public Object mget(String... keys){
List<String > queryKeys = Arrays.asList(keys);
return redisTemplate.mget(queryKeys);
}
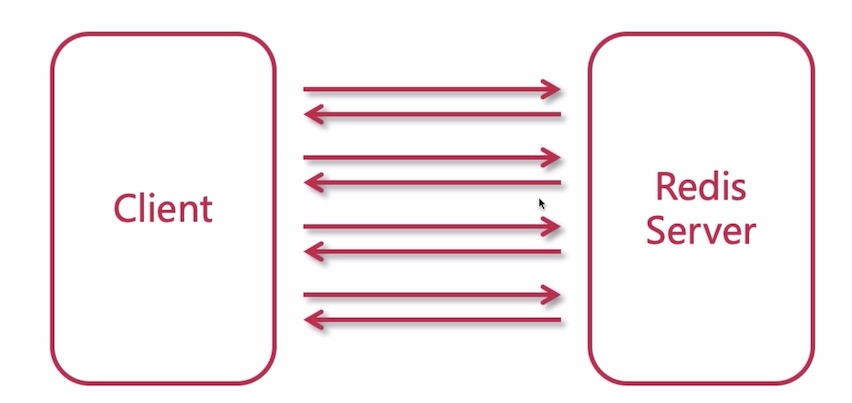
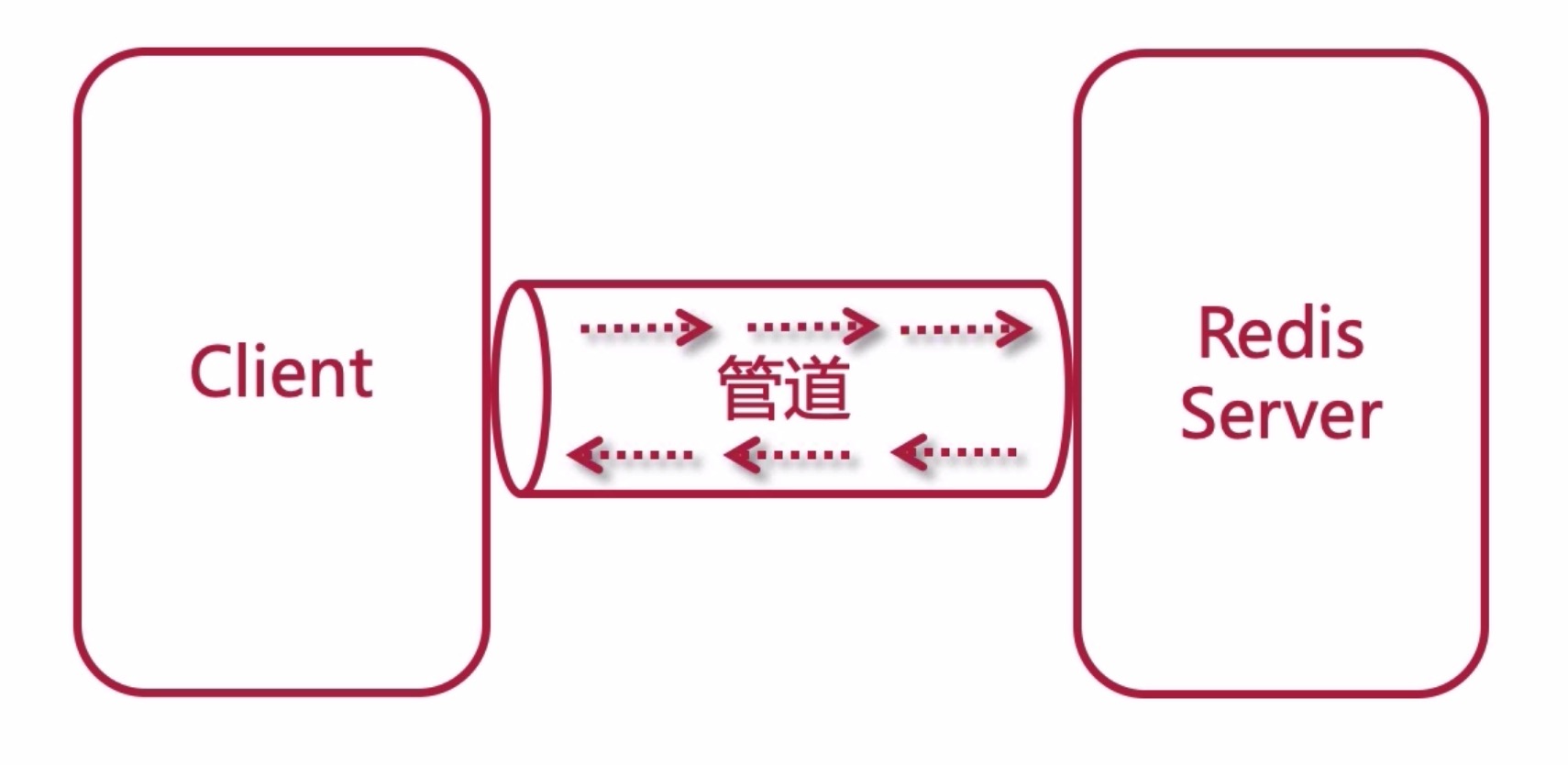
pipeline 批量查询优化
一般的数据处理客户端和服务端通过socket通讯,处理完毕之后关闭,总是有损耗的;
通过pipeline管道操作在一次连接中完成多次数据处理,处理完成之后关闭管道
/**
* 批量查询,管道pipeline
* @param keys
* @return
*/
public List<Object> batchGet(List<String> keys) {
// nginx -> keepalive
// redis -> pipeline
List<Object> result = redisTemplate.executePipelined(new RedisCallback<String>() {
@Override
public String doInRedis(RedisConnection connection) throws DataAccessException {
StringRedisConnection src = (StringRedisConnection)connection;
for (String k : keys) {
//这里可以在连接中执行几乎所有的数据
//src.set(key,value);
src.get(k);
}
return null;
}
});
return result;
}
/**
* 批量查询 pipeline
* @param keys
* @return
*/
@GetMapping("/batchGet")
public Object batchGet(String... keys){
List<String > queryKeys = Arrays.asList(keys);
return redisTemplate.batchGet(queryKeys);
}
- 0
- 0
-
分享