
ElasticSearch快速入门-基础理论部分
编辑
1714
2021-01-09
现有的数据库搜索弊端
- 空格不支持(分词)
- 拆词查询
- 搜索内容不能高亮
- 海量数据查询不能支撑
根据二八原则, 查询次数远远高于增改次数, 海量并发查询的情况下可能导致数据库无法正常提供服务; es可以从海量数据中查询用户想要的数据并且快速响应,可以提升存储量(部署在多个节点)
什么是分布式搜索引擎
- 搜索引擎: 从数据源(爬虫或者数据库)采集同步数据,进行信息处理存放到搜索引擎的节点,为用户提供检索服务,主要用来提升用户体验提供精准有效的搜索服务; 可以针对用户的搜索词进行个性化的推荐和提供营销策略优化
- 分布式存储与搜索: 提高存储容量和扩展性;
lucene VS Solr VS ElasticSearch
- 倒排序索引: 几乎所有的搜索引擎都支持
- lucene是java类库,是基于java的全文搜索引擎,不是应用程序,本质上是一个jar包,并且只支持java不支持其他语言,水平扩展很复杂;
- Solr是基于Lucene,是Apache的一个开源项目,可以部署在Tomcat或者Jenkins中,可以实现集群部署(基于zookeeper),支持分布式索引负载均衡查询自动故障转移恢复;可扩展性和容错性很高
- ES基于Lucene,分布式搜索引擎,支持rest风格的查询,可扩展性很高;提供近实时的搜索服务,支持PB级别的搜索,大数据分析; 实际应用: GitHub以前基于solr现在基于es,提供了近实时的代码库查询
ES核心术语
- 索引(index) : 类似于关系型数据库中的表
- 类型(type) : 类似于表逻辑类型, 新版本没有type了
- 文档(document) : 类似于表中的行
- 字段(fields) : 类似于表中的列
- 映射mapping : 表结构定义
- 近实时NRT : near real time
- 节点node : 每个服务器的es实例;
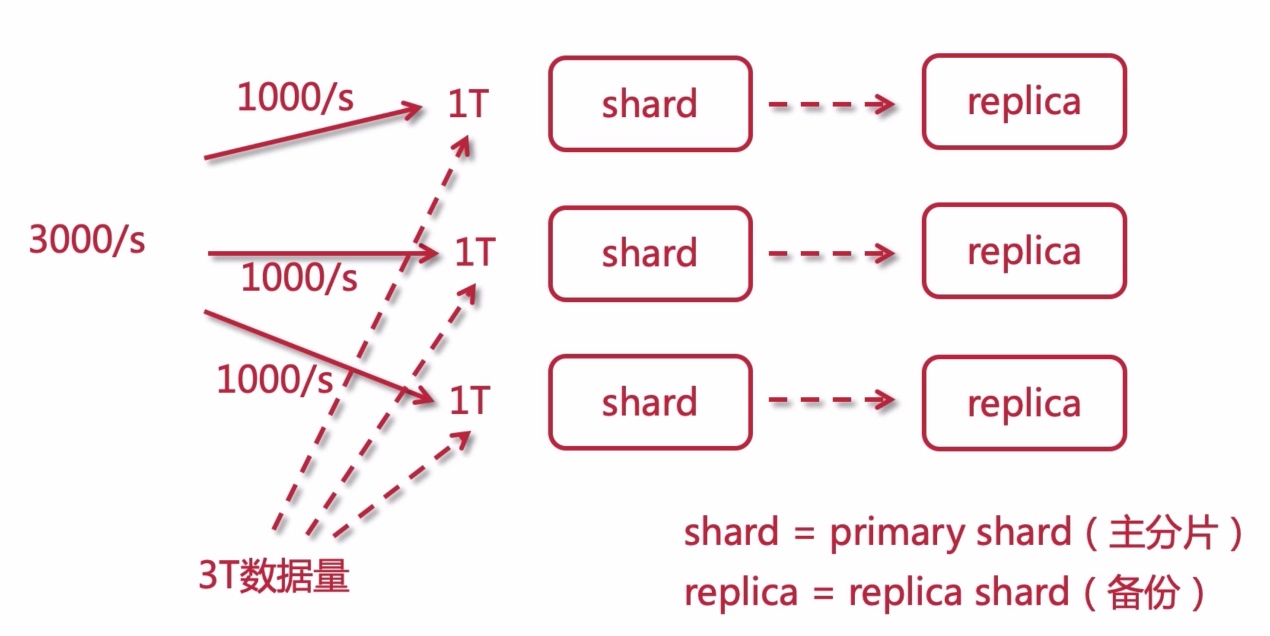
- shard replica : 数据分片与备份;
集群相关
分片(shard): 把索引库拆分为多份,分别放在不同的节点上,比如有3个节点,3个节点的所有数据内容加在一起是一个完整的索引库。分别保存到三个节点上,目的为了水平扩展,提高吞吐量。
备份(replica):每个shard的备份;
shard = primary shard
replica = replica shard
相关扩展: 可以了解一下磁盘阵列或者NAS的raid0+1
stu_index
{
id: 1001,
name: jason,
age: 19
},
{
id: 1002,
name: tom,
age: 18
},
{
id: 1003,
name: rose,
age: 22
}
ES集群架构原理
shard作为主节点,在不同的云服务上部署多个ES实例,用户请求会平分给多个shard节点,其中一个shard挂掉,会采用replica冗余备份的数据, 通过多分片(shard+replica)来实现多主多从可扩展的高可用ES服务
什么是倒排索引
正排索引 :根据文档id的值顺序排列,根据文档id获取指定文档的内容;
倒排索引: : 根据文档内容进行切分,不同分词对应对应的ids列表;倒排索引源于实际应用中需要根据属性的值来查找记录,这种索引表中的每一项都包括一个属性值和包含改属性值的各个记录地址,由于不是根据记录来确定属性,而是根据属性来确定记录的位置所以成为倒排索引
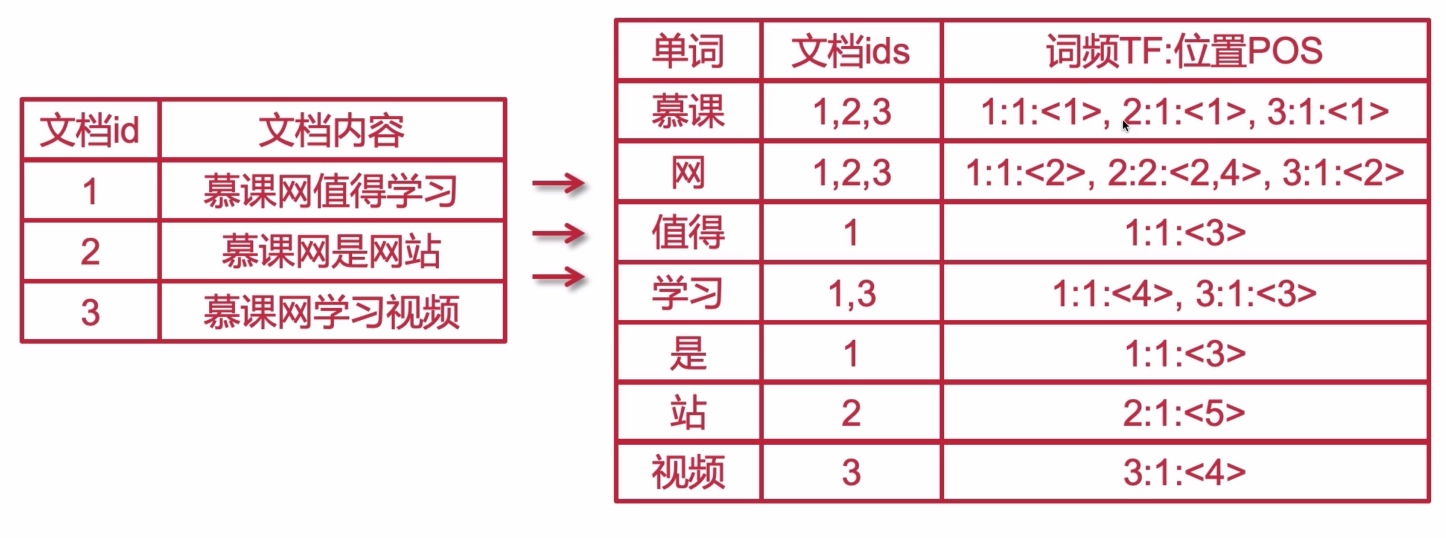
如上图,根据文档内容的分词确定词频和位置, 格式: 文档id:出现次数(词频):<对应的位置索引>
- 0
- 0
-
分享