
Redis基础
编辑为何引入Redis
一般情况下,用户的修改与查询是二八原则,在高并发的情况下,查询影响数据库性能,所以需要引入缓存机制,提高查询效率,从而降低数据库的性能瓶颈,提高吞吐量;
什么是NoSql(Not Only Sql)
NoSql全称Not Only Sql,不同于传统的项目使用纯数据库,NoSQL为互联网和大数据而生,水平扩展方便高效,具有高性能读取(每秒可达十万次),高可用等特点,主要用于存数据,做缓存;
NoSQL的常见分类
| NoSql分类 | 常见数据库 |
|---|---|
| M键值对数据库 | Redis,Memcache |
| 列存储数据库 | Hbase,Cassandra |
| 文档型数据库 | MongoDB,CouchDB |
| 图形数据库 | Neo4J,FlockDB |
什么是分布式缓存
- 提升读取速度性能;
- 分布式计算领域
- 为数据库降低查询压力
- 跨服务器缓存
- 内存式缓存
什么是Redis
- NoSQL
- 分布式缓存中间件
- key-value存储
- 提高海量数据存储和访问
- 数据存储在内存里,读取更快
- 非关系型,分布式,开源,水平扩展
分布式缓存方案与技术选型:Redis VS Memcache VS Ehcache
Ehcache
- 优点:基于Java开发,基于jvm缓存,简单,轻巧,方便
- 缺点:集群不支持,分布式不支持
Memcache
- 优点:简单的key-value存储,内存使用率较高,多核处理,多线程
- 缺点:无法容灾,无法持久化;
Redis
- 优点:丰富的数据结构,支持持久化,主从同步,故障转移,内存数据库查询效率和性能高
- 缺点:单线程,单核无法充分利用多核服务器CPU,处理大数据会降低性能
Redis作者认为设置为单线程更加方便简单,而且建议多实例使用
Redis和Memcache的主要区别在于数据结构和持久化
Redis命令行客户端基本使用
Redis默认的安装路径在/usr/local/bin 下面有Redis的客户端
redis-cli -a password shutdown:关闭redis
./redis_init_script stop:关闭redis,需要注意的是如果设置了密码需要在脚本处添加密码验证参数
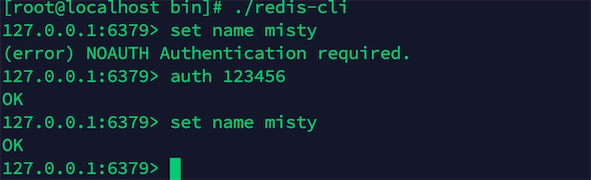
redis-cli:进入到redis客户端
auth pwd:输入密码,在Redis命令行内部需要验证的时候使用
redis-cli -a password ping:查看是否存活,如果服务正常返回pong
Redis的数据类型
key 相关
keys * 查看所有key,支持通配符, keys a*,keys *a,查询以a开头和结尾的key
type [key] :查看key的对应的数值类型;
从海量数据中查询某一固定前缀的key
鉴于keys命令在数据量过大的情况下会造成卡顿问题,可以使用scan
进行优化:scan cursor [MATCH pattern] [COUNT count ]
- 基于游标的迭代器,需要基于上一次的游标延续之前的迭过程
- 以0作为游标开始一次新的迭代,直到命令返回游标0完成一次遍历
- 不保证每次执行都返回某个给定数量的元素,支持模糊查询
- 一次返回数量不可控,只能是大概率符合count参数
scan 0 match user* count 10第一次查询从0开始,返回游标和user开头的key期望返回十个结果集(实际不一定有十个),下次查询从游标处开始,因为是分批查询所以花费的总体时间比key命令长但是不会造成卡顿,另外查询的结果可能重复,可以通过hashset来去重;
string类型
set key value:设置缓存
get key:获得缓存
del key:删除缓存
setnx rekey data:设置已经存在的key返回0,不会覆盖原有值,不存在则设置新的key-value返回1
set key value ex time:设置带过期时间的数据
expire key:为指定的key设置过期时间
ttl:查看剩余时间,-1永不过期,-2过期
append key [str]:合并字符串,在原key的基础上追加一个新的字符串
strlen key:字符串长度
incr key:累加1
decr key:累减1
incrby key num:累加给定数值
decrby key num:累减给定数值
注意累加和累减必须针对数值型数据操作
getrange key start end:截取数据,end=-1 代表截取到末尾
setrange key start newdata:从start位置开始替换数据
mset key1 value1 key2 value2 ......:连续设值
mget key1 key2 key3 ...:连续取值
msetnx:连续设置,如果存在则不设置,注意该条命令只要有一个key已经存在则全部不会设置
其他
select index:切换数据库,总共默认16个,在redis.conf可以设置数据库个数
flushdb:删除当前下边db中的数据
flushall:删除所有db中的数据
hash类型
hash: 类似map,存储结构化数据结构,比如存储一个对象(不能有嵌套对象)
基本语法:hset key property1 value1 property2 value2 ... 例如hset user name misty 创建一个hash类型的user对象,属性为name,值为misty;
hget user name:获得用户对象中name的值
hmset:设置对象中的多个键值对,hmset user age 18 phone 1234567,现在新版本5.x的hset 也可以添加多个,3.x必须使用hmset才能添加多个属性值;
hmget:获取对象中多个属性对应的值,hmget user age phone
hgetall user:获得整个对象的内容
hincrby user age 2:累加属性,只有对数值型的属性值才会有用
hincrbyfloat user age 2.2:累加浮点型类型的属性
hlen user:有多少个属性
hexists user age:判断属性是否存在
hkeys user:获得所有属性
hvals user:获得所有值
hdel user property:删除对象的属性;hdel user name
List类型
list:[a, b, c, d, …]有序列表,可以有相同的数据
基本使用
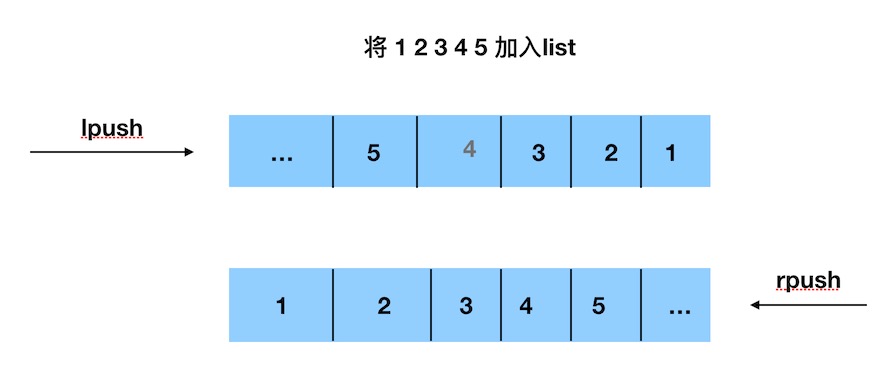
lpush list 1 2 3 4 5:构建一个list,从左边开始存入数据
rpush list 1 2 3 4 5:构建一个list,从右边开始存入数据
lrange list start end:获得数据
lpop list:从左侧开始拿出一个数据
rpop list:从右侧开始拿出一个数据
llen list:list长度
lindex list index:获取list指定下标的值
lset list index value:把某个下标的值替换
linsert list before/after value newvalue:以某个值为参照,插入一个新数据到队列
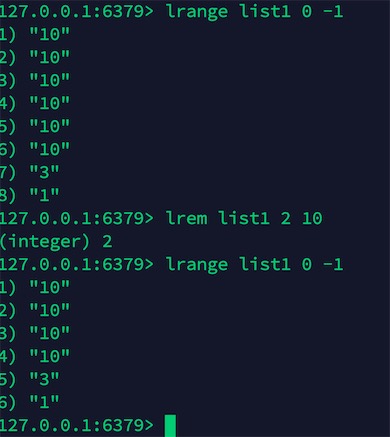
lrem list num value:删除几个值相同的数据,lrem list 2 10 删除队列中两个值为10的数据,返回删除的个数
ltrim list start end:截取值,替换原来的list,范围外的数据丢弃
set类型
Set类型数据为无序集合,会自动去除重复数据
基本使用
sadd set value1 value2 value3 value4 ...添加数据到set
smembers set 查看set集合的元素
scard set 查看set集合元素个数;
sismember set 2 查看set集合是否存在某个元素,存在返回1,不存在返回0;
srem set 2 删除集合中的某个元素,删除成功返回1;
spop set num 从集合中随机出栈几个元素;出栈的元素会被移除
srandmember set num 从集合中随机取出几个元素;集合元素不改变
smove set1 set2 10将set1中的元素10出栈,添加到set2中
差集,交集与并集
差集取值,sdiff set1 set2列出set1中有的但是在set2中没有的元素
交集取值sinter set1 set2 列出set1和set2都有的元素
并集取值 sunion set1 set2合并两个集合,去除重复元素;
zset类型
sorted set:
sorted set:排序的set,可以去重可以排序,比如可以根据用户积分做排名,积分作为set的一个数值,根据数值可以做排序。set中的每一个memeber都带有一个分数
基本使用
zadd zset 10 value1 20 value2 30 value3:设置member和对应的分数
zrange zset 0 -1:查看所有zset中的元素
zrange zset 0 -1 withscores:查看所有zset中的元素,带有分数
zrank zset value:获得某个值对应的下标
zscore zset value:获得某个值对应的分数
zcard zset:统计个数
zcount zset score1 score2:统计两个分数之间的元素个数(闭区间)
zrangebyscore zset score1 score2:查询分数之间的元素(包含分数1 分数2)
zrangebyscore zset score1 score2 withscores:查询分数之间的元素(包含分数1 分数2),并且带有分数
zrangebyscore zset (score1 (score2:查询分数之间的元素(如果分数前加入(代表不包含分数1 和 分数2)
zrangebyscore zset score1 score2 limit start end:查询分数之间的元素(包含分数1 分数2),获得的结果集再次根据下标区间做查询
zrem zset value:删除指定元素
参考文档
- 0
- 0
-
分享